Orchestrating the Iterative Development of Custom Models

Azure AI Document Intelligence provides a robust framework of prebuilt and custom models for extracting structured data from documents at scale.
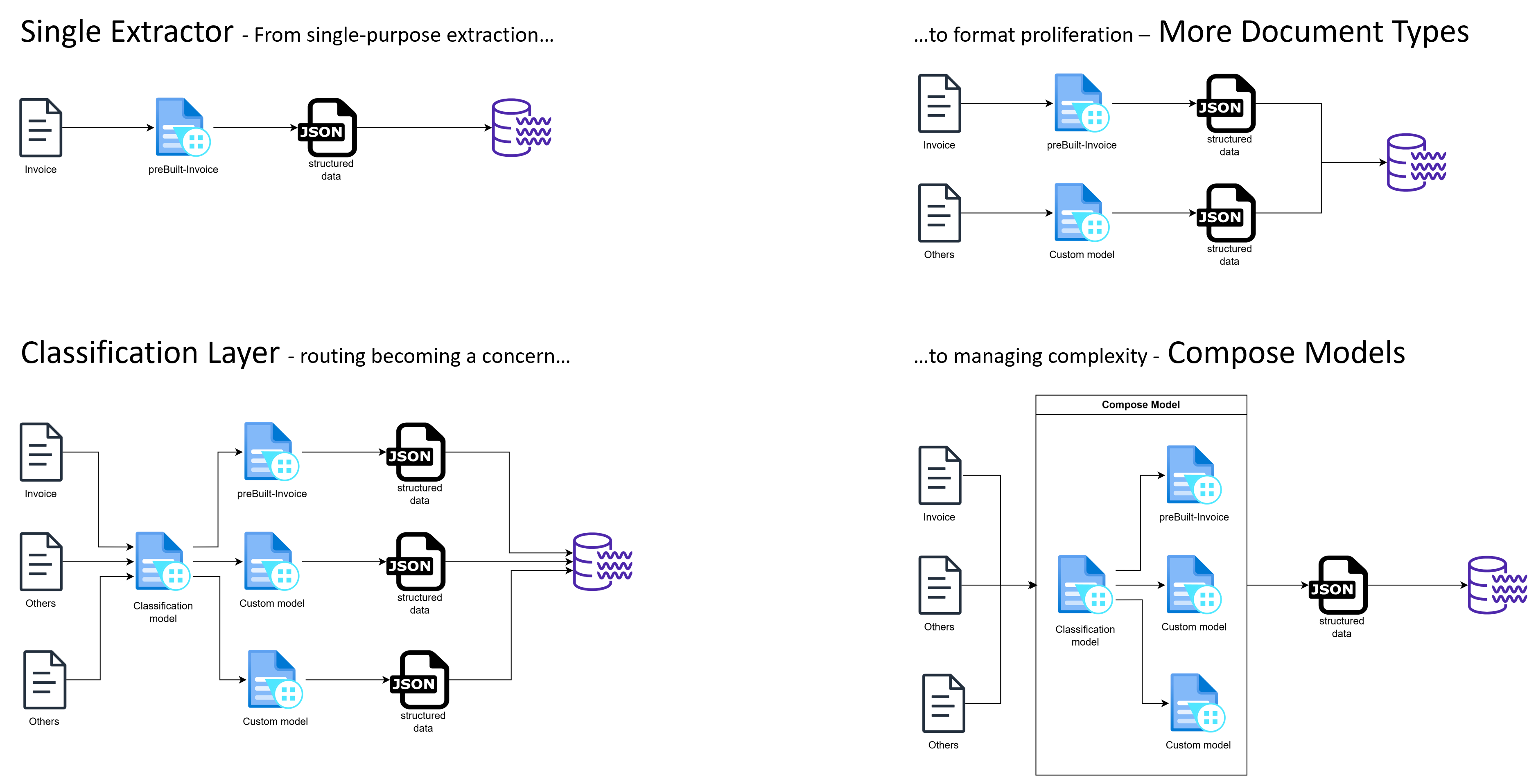
For standardized document types, Azure AI Document Intelligence provides prebuilt models that achieve high accuracy with minimal setup. However, enterprise systems quickly move beyond a single schema, ingesting documents from multiple sources with evolving layouts.
As soon as new document formats are introduced, complexity shifts from model accuracy to orchestration.
The technical implementation of an extraction system is not a single event, but an iterative process.
Document extraction systems typically begin with a single extractor. As new document layouts appear, multiple custom extractors are introduced. Routing logic then becomes difficult to maintain, leading to the adoption of a classifier to identify document type.
Finally, composed models re-establish a single integration surface by combining the classifier and extractors behind one endpoint.
No model is 100% accurate forever. As documents drift, confidence scores drop. Without an explicit management layer, low-confidence outputs either block pipelines or silently corrupt downstream systems.
At this point, confidence is no longer a metric to observe, but a decision the system must make.
The confidence gate makes extraction failures explicit, defining how they are detected, contained, and reused for iterative improvement.
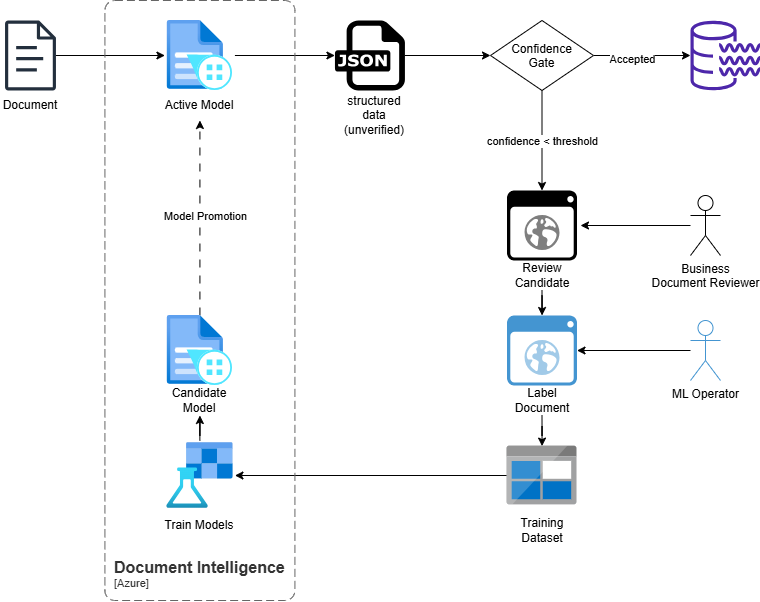
Rather than embedding failure handling directly into ingestion logic, extraction results are evaluated against a confidence gate.
Once documents are reviewed and validated, the focus shifts from decision-making to preparing data for reliable retraining.
Retraining requires more than approved documents; it requires reproducible data lineage.
Reviewed documents must be staged together with their OCR outputs and label files so that retraining can be repeated and audited.
Maintaining this lineage is a prerequisite for any iterative training process.
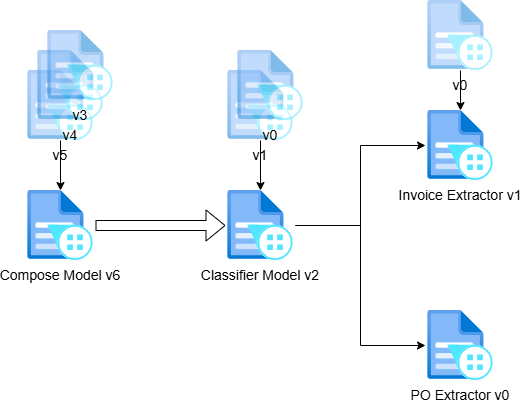
In practice, extractors, classifiers, and composed models evolve independently.
Improvements are rarely applied across all models at once, making coordination between model versions a central MLOps challenge.
Once confidence handling is in place, the primary challenge becomes orchestrating how models evolve over time, not how individual documents are extracted.
Each component in the system—the classifier, individual extractors, and the composed model—has an independent lifecycle and version lineage, yet must be coordinated deliberately. In our experience, retraining rarely happens atomically across all models; improvements are selective and incremental.
To manage this complexity, the architecture introduces a model-iteration sidecar that acts as a control plane for review tracking, dataset curation, retraining, composed model assembly. Rather than maintaining static training snapshots, training datasets are built incrementally over time, reflecting the evolving document landscape and ensuring continuity across iterations.
The ingestion application remains decoupled from the specific versions of the models. It queries a Model Registry within the Administration system to identify the current "Active" Composed Model ID.
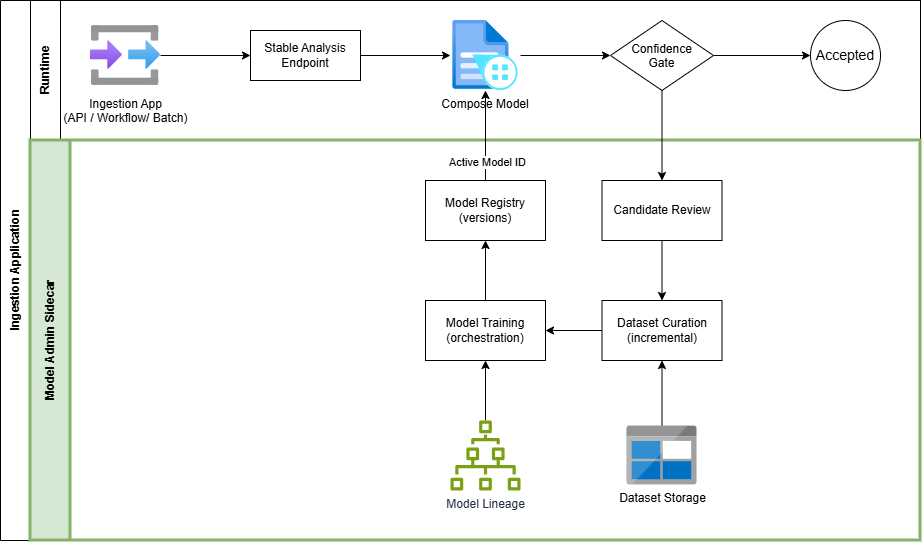
These orchestration concepts are implemented in an open-source reference sidecar that manages: Review candidates, incremental datasets, staging, retraining, model composition.
The repository focuses on control-plane logic and intentionally omits application-specific ingestion concerns.
Content Understanding becomes relevant when document variability exceeds the practical limits of layout-based extraction, complementing—not replacing—Document Intelligence.

